Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
용어 정리
monocular depth estimation

foundation model- models which are pretrained on vast amount of data
semi-supervised learning- unlabeled data를 활용하는 학습방식. labeled data로 학습된 teacher model을 가지고, unlabeled data의 pseudo depth map을 만들어, 새로운 student model에 labeled, unlabeled data를 supervised learning으로 학습시키는 방식.
zero-shot depth estimation- train set에 없는 unseen domain에 대해 depth estimation을 수행
smooth auxiliary task- semantic segmentation을 보조 task로 설정하는 직접적인 방식과 달리,
모델의 online encoder을 통과한 latent vector과 semantic segmenatation 모델의 frozen 인코더를 통과한 latent vector의 cosine similarity를 비슷하게 유도하는 방향으로 학습을 진행.
- semantic segmentation을 보조 task로 설정하는 직접적인 방식과 달리,
hard perturbation- 해당 연구는 pseudo labels에 대해 강한 perturbation을 적용함.
Motivation
기존 단점 최근 Vision분야와 NLP분야에서 foundation model을 활용한 발전이 두드러지고있다. 하지만 Monocular Depth Estimation(MDE) 분야에서의 foundation model 관련 연구는 아직 충분히 수행되지 않았다. 그 이유는 depth label을 가진 많은 수의 데이터를 확보하기가 어렵기 때문이다.
이전 연구 최근에 MiDaS(Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer, 2020) 라는 연구에서 서로 다른 방식의 depth label을 가진 데이터셋들을 한번에 학습시키는 접근으로 MDE 성능을 크게 향상시켰다. 하지만 그럼에도 사용된 학습데이터는 약 2M개로, 최근 각광받은 Segment Anything 모델의 학습데이터인 11M에 비하면 적은 수준이며, 그로 인해 특정 상황에서 매우 낮은 성능을 보이는 특징이 있다.
연구 방향 따라서, Depth Anything 연구에서는 MiDaS의 맥락을 참고하여, 추가적인 unlabeled data들을 활용한 MDE foundation model을 만들어보고자 한다.
Methods
1) Semi-supervised learning
해당 연구에선 unlabeled dataset을 활용하기 위해, semi-supervised semantic segmentation 에서 기존 방식들을 월등히 뛰어넘은 ST++(*ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation, 2022)* 연구의 방식을 채택했다. 그 학습 방식은 아래와 같다.
- Teacher model T를 labeled dataset으로 학습시킨다.
- Teacher model에 unlabeled data들을 통과시켜 얻는 depth estimation을 pseudo label로, 모든 unlabeled dataset에 대해 얻어준다.
- Student model S를 학습시킨다. 이 때, Teacher model을 fine-tuning 하지 않고, 초기화된 모델을 labeled datset과 pseudo labeled dataset을 섞어 처음부터 학습시켜준다.
위의 3번 과정 에서, 저자들은 한가지 문제를 마주한다. labeled data와 pseudo label을 혼합해 학습시켜주었음에도 ST++와 같은 비약적 성능향상이 없었다는 점 이다. (아래 test 데이터셋 별 성능표의 1,2째 행을 참조해보면 미약한 성능향상을 확인할 수 있다.)

논문의 저자들은 미약한 성능향상 이란 문제의 원인을 ST++연구와 해당 연구의 학습 데이터셋 규모 차이에서 찾았다.
ST++ 에서는 약 100~1000+ 개의 labeled image를 사용했지만, 해당 연구에서는 1.5M개의 labeled image를 사용해 학습을 한다. 이처럼, 이미 좋은 퀄리티의 labeled image가 많을 경우, 학습하는 모델이 unlabeled images에서 추가적인 정보들을 얻으려 하지 않는다고 저자는 추측하였다.
저자의 돌파구는 다음과 같다. unlabeled images에 강한 perturbation을 줘, 해당 이미지들로부터 정보를 얻는 것이 더 어렵도록 유도해 보았고 그 방식은 test 데이터셋에서 성능향상을 만들었다. (위의 table 2,3째 행을 비교해보면 알 수 있다.)
1.1) Perturbation Details
저자는 image perturbation 방식들로 strong color distortions(color jittering, Gaussian blurring)과 strong spatial distortion(CutMix)을 주었다.
(labeled images에는 perturbation을 주지 않은 이유를 해당 논문에선 직접 언급하지 않았으나, ST++연구의 같은 접근에 대한 설명을 참조해 보면, labeled data의 clean distribution을 헤칠까봐 그런 것 으로 추측된다.)
Perturbation에 대한 Loss function은 다음처럼 구성된다.
우선 Cutmix를 수행해준다.


$u_{ab}$: mixed image
$u_a, u_b$: unlabled image
$M$: binary mask

다음, 각 Mask에 대해 Student, Teacher model에 대한 Affine-inverient Loss로 Loss를 계산해준다. 이 때 Teacher model의 input으론 color distortion이 없는 깨끗한 이미지를 사용한다.

전체 Loss는 다음과 같게 된다.
2) Semantic-assisted preception
논문의 저자들은 depth estimation의 보조 task로 semantic segmentation을 준 이전 연구들을 바탕으로 실험을 진행하였으나, 성능향상에 실패하였다.
저자는 실패의 원인을 다음과 같이 추측했다. semantic segmentation은 discrete하게 결과를 표현하기 때문에 더 복잡한 regression인 depth estimation의 의미적 정보를 많이 잃을 수 있어 추가적인 성능향상이 어렵다는 설명이다.
따라서, 결과를 비교하지 않고, semantic segmentation model의 인코더와, depth estimation encoder의 latent vector이 비슷해지도록 유도해 semantic information을 덜 잃도록 실험을 진행하였다.

Loss는 다음과 같다.

그 결과로 모든 test dataset에 대해 metric이 소폭 상향했음을 알 수 있다.(위 표의 3,4 째 줄)
3) Student model’s overall training process
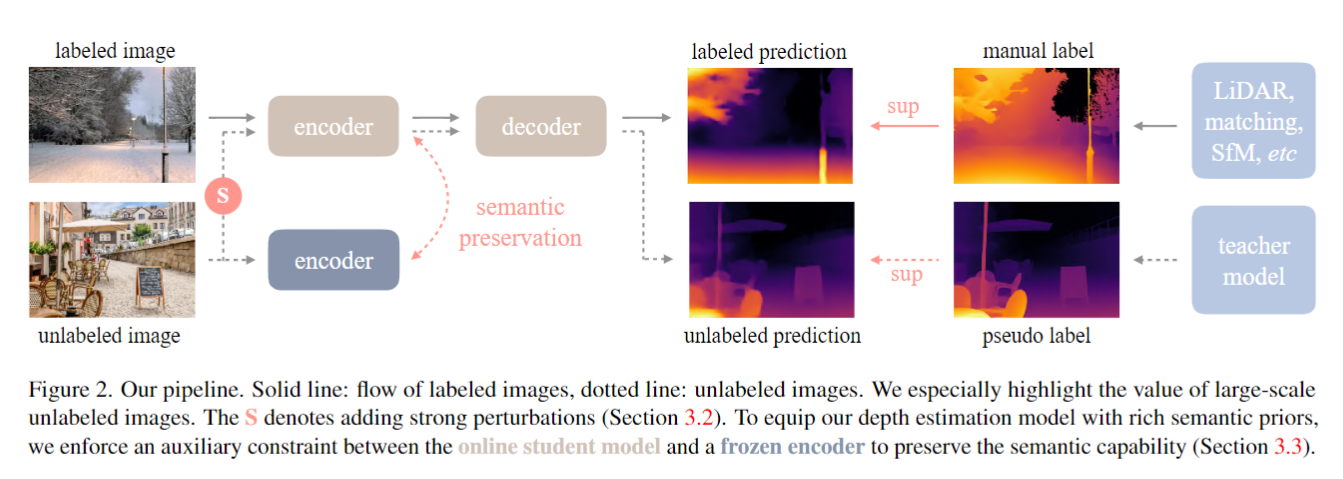
전체적인 학습 pipeline은 위와 같다.
Quantitative comparsion
Abs-Rel: Absolute Relative difference
$\delta_1$: percentage ofmax(d∗/d,d/d∗)<1.25

Zero-shot relative depth estimation 의 결과.
- Depth Anything 모델의 ViT-Small 모델이 MiDaS v3.1(2023)의 ViT-Large 모델보다 더 좋은 성능을 보이는 점이 눈에 띈다.
- 또한, 모든 test dataset에서 압도적인 성능을 보이는 점 또한 눈에 띈다.

Zero-shot metric depth estimation 결과.
- relative depth esitmation으로 학습한 depth anything 모델을 metric scale로 fine-tuning 시킨 결과로, Depth Anything이 더 좋은 결과를 보임을 알 수 있다.
Qualitative Results

주행 데이터 KITTI 데이터셋

Indoor NYUv2 데이터

3D animation, Sintel 데이터셋
Takeaways
- Monocular Depth Estimation을 위한 Unlabeled images를 pseudo labeling으로 최대한 활용해 주었다.
- Strong perturbation을 이용해 추가적인 visual information을 추출하도록 유도하였다.
- 별도의 encoder을 이용해 latent vector끼리 cosine similarity을 비슷해지도록 일반 auxiliary task보다 섬세하게 유도한 점이 범용적으로 사용될 수 있는 방법이라 생각된다.
References
Depth Anything: https://arxiv.org/abs/2401.10891
MiDaS : https://arxiv.org/abs/1907.01341
ST++ : https://arxiv.org/abs/2106.05095
https://docs.ultralytics.com/ko/models/sam/
'Paper Reviews' 카테고리의 다른 글
| Batch Normalizaion(2015) 설명 (0) | 2023.09.03 |
|---|---|
| Deep Networks with Stochastic Depth, ECCV 2016 (0) | 2023.08.30 |
| 1D Convolutional Neural Networks and Applications - A Survey (0) | 2023.08.30 |