30일 첼린지 1일차, 금요일

forward 순
'I like staying at home.' 이란 문장이, transformer 모델에 들어가서 output으로 나오는 과정을 원리와 데이터의 흐름을 중심으로 차근차근 생각해보았다.
0. input sentence tokenizing
input >>> 'I like staying at home.'
tokenized >>> ['i', 'like', 'stay', '##ing', 'at', 'home', '.']
output(token_to_id) >>> [151, 3751, 6758, 19, 534, 616, 1, <pad>, <pad>, ..., <pad>]
output.shape = (max_seq_len, )
WordPiece(BERT), 은전한닢, Mecab 등의 tokenizer로 input sentence를 tokenize 한다.
tokenize된 결과는 문장이 인덱스로 변한다.
+ tokenizer 들이 학습되는 알고리즘 -> BPE, WordPiece, SentencePiece 등등
1. Input Embedding layer
input >>> [151, 3751, 6758, 19, 534, 616, 1, <pad>, <pad>, ..., <pad>]
input.shape = (max_seq_len, )
output.shape = (max_seq_len, d_model)
각 인덱스에 해당하는 Embedding vector들로 구성된 Matrix가 다음 레이어로 넘어간다.
임베딩벡터의 차원수인 d_model 의 크기는 논문에선 512로, dense vector의 크기이며, 트랜스포머의 인코더와 디코더에서의 입출력 크기이다.
2. Positional Encoding
input.shape = (max_seq_len, d_model)
output.shape = (max_seq_len, d_model)
(제일 직관적으로 이해가 안가는 부분)
순차적으로 입력받는게 아니라, 모든 과정들이 병렬처리가되는 transformer에, 같은 단어가 한 문장에 들어올 경우, 완전히 같은 벡터값을 갖게되고, 문장의 위치에 따라 단어의 뜻은 다르기에 이런 특성을 살리기위해 특정 고정된 값들을 더해주는 과정이다. 이 더해지는 값들은 학습되는 파라미터가 아니고, 그저 이전 출력에 더해지는 고정된 값이다.
따라서 input embedding 에서 나온 (max_seq_len, d_model) 사이즈와 똑같은 서로다른 값들로 채워진 matrix를(지수함수모양을 sin과 cos들 태운, -1,1사이의 값들) input embedding layer의 출력에 더해준다.
이로서 병렬처리를 해도 위치정보가 고려될 수 있다고 한다.
그리고 덧셈연산이기에, shape의 변화는 없다.
3. multi-head self-attention
input.shape = (max_seq_len, d_model)
output.shape = (max_seq_len, d_model)
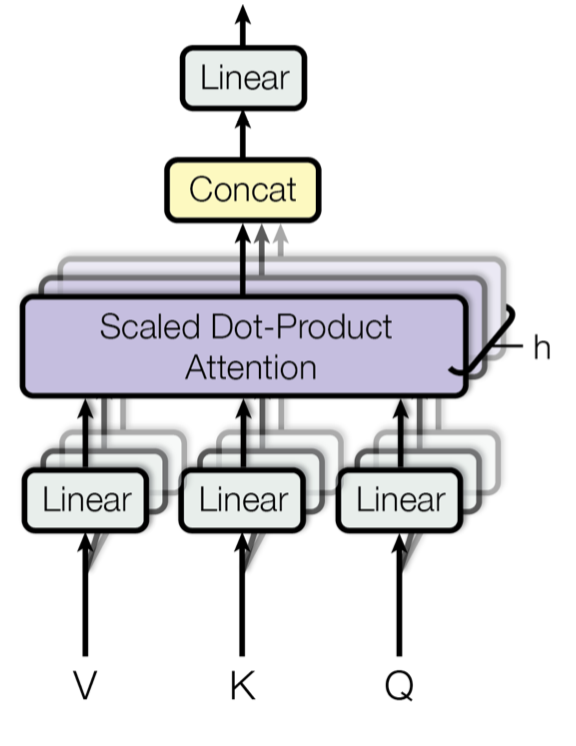
multi-head self attention layer
트랜스포머에 들어온 input이 가장 먼저 만나는 attention layer 인 multi-head self-attention layer을 지나가는 과정은 다음과 같다. 복잡해서 몇단계로 나누어보았다.
3-1/2 <입력에서 num_heads 개의 Query, Key, Value vectors 를 만들기>
input.shape = (max_seq_len, d_model)
output.shape =
Q >>> num_heads * (max_seq_len, d_model/num_heads)
K >>> num_heads * (max_seq_len, d_model/num_heads)
V >>> num_heads * (max_seq_len, d_model/num_heads)
앞에서 들어온 positional encoding을 마친 (max_seq_len, d_model) 모양의 입력이
num_heads 개의 (d_model, d_model / num_heads) 모양인 행렬인 Q,K,V 의 weight matrix와 행렬곱된다. 그 결과는 num_heads개의 (max_seq_len, d_model / num_heads) 모양인 Query, Key, Value vector이다. (Q,K,V weight matrix는 training 시 학습됨.)
< 예를들어, 이런 setting일 경우, Q K V matrix의 모양은? >
max_seq_len = 50
d_model = 512
num_heads = 8
Q, K, V 모두 (50, 64)모양의 8개의 matrix를 갖는다. 우영우 보고싶다.
여기서 한번에 계산하지 않고, 굳이 dense 차원을 8개로 나누어서 attention 계산을 해주려는 이유는,
구글 연구진들의 연구결과 한번의 attention 계산보다 여러번 병렬로 수행하는게 결과적으로 효과적이었다 한다. 효과적인 이유를 끼워맞추면? 더 다양한 시각으로 문장을 볼 수 있었기 때문이아닐까라고 한다.
예를들어 'I like staying at home' 이라는 문장에서, 나누지 않고 한번에 처리하면 staying이 home이랑 가장 연관있다고 보겠지만, 나누어서 보면, 자세히보니 like 와 staying도 꽤 관련이 있고, home이랑 staying도 관련이 있다는 결과가 나올 수 있는것처럼, 더 세세하게 관찰할 수 있는거라고 한다.
3-2/2< Scaled dot product attention 계산>
input.shape =
Q >>> num_heads * (max_seq_len, d_model/num_heads)
K >>> num_heads * (max_seq_len, d_model/num_heads)
V >>> num_heads * (max_seq_len, d_model/num_heads)
output >>> (max_seq_len, d_model)
가독성을위해 이렇게 전제하고 shape을 표시해본다!
max_seq_len = 50
d_model = 512
num_heads = 8
이제, 8개의 Query(50, 64) 벡터 에서 하나의 단어에 해당하는 벡터인(64,)를 8개마다 하나씩 뽑아준다.
★ -- max_seq_len번 반복...
Query 마다 문장 순서대로 하나의 벡터값(64,)을 뽑아 대응하는 Key 벡터(50, 64) 와 dot product 를 해 (50,)모양 값을 얻는다. 이 값(50,)을 root(d_k = d_model/num_heads) 로 나누어 scaling 해줘 같은 모양인 (50,) 값을 얻는다. 이 값은 query에서 뽑은 그 단어와 input 문장 각각의 단어들과의 관계(거리)를 뜻한다. 이 값 (50,)을 softmax 해준거를 attention distribution 이라고 한다. 이는 향후 Key vector과 곱해진다.
attention distribution.shape >>> num_heads * (max_seq_len,)
(scaling을 하는 이유--뇌피셜 : 아무래도 d_k 차원을 sum()하는 연산이 있다보니, 값은 커지는 경향을 보일테고, 값이 커지면 전체 학습과정에서 그 레이어 결과의 분산이 점점 커지므로, 학습에 부정적인 요인을 주지 않을까 싶다.)
이 attention distribution(50,)을 그대로 Value vector (50,64)와 곱해준다.
>>> attnetion_distribution * value_matrix = (50,)(50,64) = (50,64)
이 (50,64)벡터는 query에서 뽑은 단어와의 관련도로 본, 문장의 분산표현이다.
다시말하면, 그냥 query에서 뽑은 단어로 self attention 계산을 한 결과이다.
이 벡터를 문장 길이차원에서의 sum() 연산을 통해 값들을 다 더해줘서, (64,) 모양의 1차원 벡터를 구한다.
이 값이 Attention value(64,)=(d_model/num_heads) 이며, 이 별표안의 과정을 query의 모든 단어들에 대해서 수행한다!
★
위에 별표 과정을 Query 벡터의 모든 단어들에 대해 수행한 값들 8*(50,64)을 모두 다시 concatnate 한, (50,512)= (max_seq_len, d_model) 이 multi-head self-attention layer의 최종 output.shape이다.
4. Add & Norm
input.shape = (max_seq_len, d_model), (max_seq_len, d_model)
output.shape = (max_seq_len, d_model)
gradient 안정화를 위해, skip-connection 부여 + 값 normalization.
5. Feed Forward layer
input.shape = (max_seq_len, d_model)
output.shape = (max_seq_len, d_model)
'AI > cs224n' 카테고리의 다른 글
| Stanford CS224N NLP with Deep Learning | Spring 2022 | Guest Lecture: Scaling Language Models 강의 요약 (0) | 2022.07.31 |
|---|